Helping platform leaders, architects, engineers, and operators build scalable real time data platforms.
1/23/2019
Reading time:15 mins
Cassandra Datacenter & Racks
by Adron
This last post in this series is Distributed Database Things to Know: Consistent Hashing.Let’s talk about the analogy of Apache Cassandra Datacenter & Racks to actual datacenter and racks. I kind of enjoy the use of the terms datacenter and racks to describe architectural elements of Cassandra. However, as time moves on the relationship between these terms and why they’re called datacenter and racks can be obfuscated.Take for instance, a datacenter could just be a cloud provider, an actual physical datacenter location, a zone in Azure, or region in some other provider. What an actual Datacenter in Cassandra parlance actually is can vary, but the origins of why it’s called a Datacenter remains the same. The elements of racks also can vary, but also remain the same.Origins: Racks & Datacenters?Let’s cover the actual things in this industry we call datacenter and racks first, unrelated to Apache Cassandra terms.Racks: The easiest way to describe a physical rack is to show pictures of datacenter racks via the ole’ Google images.A rack is something that is located in a data-center, or even just someone’s garage in some odd scenarios. Ya know, if somebody wants serious hardware to work with. The rack then has a number of servers, often various kinds, within that rack itself. As you can see from the images above there’s a wide range of these racks.Datacenter: Again the easiest way to describe a datacenter is to just look at a bunch of pictures of datacenter, albeit you see lots of racks again. But really, that’s what a datacenter is, is a building that has lots and lots of racks.However in Apache Cassandra (and respectively DataStax Enterprise products) a datacenter and rack do not directly correlate to a physical rack or datacenter. The idea is more of an abstraction than hard mapping to the physical realm. In turn it is better to think of datacenter and racks as a way to structure and organize your DataStax Enterprise or Apache Cassandra architecture. From a tree perspective of organizing your cluster, think of things in this hierarchy.ClusterDatacenter(s)Rack(s)Server(s)Node (vnode)Apache Cassandra DatacenterAn Apache Cassandra Datacenter is a group of nodes, related and configured within a cluster for replication purposes. Setting up a specific set of related nodes into a datacenter helps to reduce latency, prevent transactions from impact by other workloads, and related effects. The replication factor can also be setup to write to multiple datacenter, providing additional flexibility in architectural design and organization. One specific element of datacenter to note is that they must contain only one node type:Transactional: A standard Cassandra node.DataStax Enterprise Graph: The Graph database offering from Datastax.DataStax Enterprise Analytics: An integration with Apache Spark.DataStax Enterprise Search: Integration with Apache Solr.DataStax Enterprise Search Analytics: Search queries within analytics jobs.Depending on the replication factor, data can be written to multiple datacenters. Datacenters must never span physical locations.Each datacenter usually contains only one node type. The node types are:Transactional: Previously referred to as a Cassandra node.DSE Graph: A graph database for managing, analyzing, and searching highly-connected data.DSE Analytics: Integration with Apache Spark.DSE Search: Integration with Apache Solr. Previously referred to as a Solr node.DSE SearchAnalytics: DSE Search queries within DSE Analytics jobs.Apache Cassandra RacksAn Apache Cassandra Rack is a grouped set of servers. The architecture of Cassandra uses racks so that no replica is stored redundantly inside a singular rack, ensuring that replicas are spread around through different racks in case one rack goes down. Within a datacenter there could be multiple racks with multiple servers, as the hierarchy shown above would dictate.To determine where data goes within a rack or sets of racks Apache Cassandra uses what is referred to as a snitch. A snitch determines which racks and datacenter a particular node belongs to, and by respect of that, determines where the replicas of data will end up. This replication strategy which is informed by the snitch can take the form of numerous kinds of snitches, some examples include;SimpleSnitch – this snitch treats order as proximity. This is primarily only used when in a single-datacenter deployment.Dynamic Snitching – the dynamic snitch monitors read latencies to avoid reading from hosts that have slowed down.RackInferringSnitch – Proximity is determined by rack and datacenter, assumed corresponding to 3rd and 2nd octet of each node’s IP address. This particular snitch is often used as an example for writing a custom snitch class since it isn’t particularly useful unless it happens to match one’s deployment conventions.In the future I’ll outline a few more snitches, how some of them work with more specific detail, and I’ll get into a whole selection of other topics. Be sure to subscribe to the blog, the ole’ RSS feed works great too, and follow @CompositeCode for blog updates. For discourse and hot takes follow me @Adron.Distributed Database Things to Know SeriesConsistent HashingApache Cassandra Datacenter & Racks (this post) 47.666712 -122.383132 Project Repo: Interoperability Black BoxFirst steps. Let’s get .NET installed and setup. I’m running Ubuntu 18.04 for this setup and start of project. To install .NET on Ubuntu one needs to go through a multi-command process of keys and some other stuff, fortunately Microsoft’s teams have made this almost easy by providing the commands for the various Linux distributions here. The commands I ran are as follows to get all this initial setup done.wget -qO- https://packages.microsoft.com/keys/microsoft.asc | gpg --dearmor > microsoft.asc.gpgsudo mv microsoft.asc.gpg /etc/apt/trusted.gpg.d/wget -q https://packages.microsoft.com/config/ubuntu/18.04/prod.listsudo mv prod.list /etc/apt/sources.list.d/microsoft-prod.listsudo chown root:root /etc/apt/trusted.gpg.d/microsoft.asc.gpgsudo chown root:root /etc/apt/sources.list.d/microsoft-prod.listAfter all this I could then install the .NET SDK. It’s been so long since I actually installed .NET on anything that I wasn’t sure if I just needed the runtime, the SDK, or what I’d actually need. I just assumed it would be safe to install the SDK and then install the runtime too.sudo apt-get install apt-transport-httpssudo apt-get updatesudo apt-get install dotnet-sdk-2.1Then the runtime.sudo apt-get install aspnetcore-runtime-2.1Alright. Now with this installed, I wanted to also see if Jetbrains Rider would detect – or at least what would I have to do – to have the IDE detect that .NET is now installed. So I opened up the IDE to see what the results would be. Over the left hand side of the new solution dialog, if anything isn’t installed Rider usually will display a message that X whatever needs installed. But it looked like everything is showing up as installed, “yay for things working (at this point)!”Next up is to get a solution started with the pertinent projects for what I want to build.For the next stage I created three projects.InteroperationalBlackBox – A basic class library that will be used by a console application or whatever other application or service that may need access to the specific business logic or what not.InteroperationalBlackBox.Tests – An xunit testing project for testing anything that might need some good ole’ testing.InteroperationalBlackBox.Cli – A console application (CLI) that I’ll use to interact with the class library and add capabilities going forward.Alright, now that all the basic projects are setup in the solution, I’ll go out and see about the .NET DataStax Enterprise driver. Inside Jetbrains Rider I can right click on a particular project that I want to add or manage dependencies for. I did that and then put “dse” in the search box. The dialog pops up from the bottom of the IDE and you can add it by clicking on the bottom right plus sign in the description box to the right. Once you click the plus sign, once installed, it becomes a little red x.Alright. Now it’s almost time to get some code working. We need ourselves a database first however. I’m going to setup a cluster in Google Cloud Platform (GCP), but feel free to use whatever cluster you’ve got. These instructions will basically be reusable across wherever you’ve got your cluster setup. I wrote up a walk through and instructions for the GCP Marketplace a few weeks ago. I used the same offering to get this example cluster up and running to use. So, now back to getting the first snippets of code working.Let’s write a test first.[Fact]public void ConfirmDatabase_Connects_False(){ var box = new BlackBox(); Assert.Equal(false, box.ConfirmConnection());}In this test, I named the class called BlackBox and am planning to have a parameterless constructor. But as things go tests are very fluid, or ought to be, and I may change it in the next iteration. I’m thinking, at least to get started, that I’ll have a method to test and confirm a connection for the CLI. I’ve named it ConfirmConnection for that purpose. Initially I’m going to test for false, but that’s primarily just to get started. Now, time to implement.namespace InteroperabilityBlackBoxusing System;using Dse;using Dse.Auth;namespace InteroperabilityBlackBox{ public class BlackBox { public BlackBox() {} public bool ConfirmConnection() { return false; } }}That gives a passing test and I move forward. For more of the run through of moving from this first step to the finished code session check out this[embedded content]By the end of the coding session I had a few tests.using Xunit;namespace InteroperabilityBlackBox.Tests{ public class MakingSureItWorksIntegrationTests { [Fact] public void ConfirmDatabase_Connects_False() { var box = new BlackBox(); Assert.Equal(false, box.ConfirmConnection()); } [Fact] public void ConfirmDatabase_PassedValuesConnects_True() { var box = new BlackBox("cassandra", "", ""); Assert.Equal(false, box.ConfirmConnection()); } [Fact] public void ConfirmDatabase_PassedValuesConnects_False() { var box = new BlackBox("cassandra", "notThePassword", ""); Assert.Equal(false, box.ConfirmConnection()); } }}The respective code for connecting to the database cluster, per the walk through I wrote about here, at session end looked like this.using System;using Dse;using Dse.Auth;namespace InteroperabilityBlackBox{ public class BlackBox : IBoxConnection { public BlackBox(string username, string password, string contactPoint) { UserName = username; Password = password; ContactPoint = contactPoint; } public BlackBox() { UserName = "ConfigValueFromSecretsVault"; Password = "ConfigValueFromSecretsVault"; ContactPoint = "ConfigValue"; } public string ContactPoint { get; set; } public string UserName { get; set; } public string Password { get; set; } public bool ConfirmConnection() { IDseCluster cluster = DseCluster.Builder() .AddContactPoint(ContactPoint) .WithAuthProvider(new DsePlainTextAuthProvider(UserName, Password)) .Build(); try { cluster.Connect(); return true; } catch (Exception e) { Console.WriteLine(e); return false; } } }}With my interface providing the contract to meet.namespace InteroperabilityBlackBox{ public interface IBoxConnection { string ContactPoint { get; set; } string UserName { get; set; } string Password { get; set; } bool ConfirmConnection(); }}Conclusions & Next StepsAfter I wrapped up the session two things stood out that needed fixed for the next session. I’ll be sure to add these as objectives for the next coding session at 3pm PST on Thursday.The tests really needed to more resiliently confirm the integrations that I was working to prove out. My plan at this point is to add some Docker images that would provide the development integration tests a point to work against. This would alleviate the need for something outside of the actual project in the repository to exist. Removing that fragility.The application, in its “Black Box”, should do something. For the next session we’ll write up some feature requests we’d want, or maybe someone has some suggestions of functionality they’d like to see implemented in a CLI using .NET Core working against a DataStax Enterprise Cassandra Database Cluster? Feel free to leave a comment or three about a feature, I’ll work on adding it during the next session.Project Repo: https://github.com/Adron/InteroperabilityBlackBoxFile an Feature Request: https://github.com/Adron/InteroperabilityBlackBox/issues/new?template=feature_request.md SITREP = Situation Report. It’s military speak. ??♂️Apache Cassandra is one of the most popular databases in use today. It has many characteristics and distinctive architectural details. In this post I’ll provide a description and some details for a number of these features and characteristics, divided as such. Then, after that (i.e. toward the end, so skip there if you just want to the differences) I’m doing to summarize key differences with the latest release of the DataStax Enterprise 6 version of the database.Cassandra CharacteristicsCassandra is a linearly scalable, highly available, fault tolerant, distributed database. That is, just to name a few of the most important characteristics. The Cassandra database is also cross-platform (runs on any operating systems), multi-cloud (runs on and across multiple clouds), and can survive regional data center outages or even in multi-cloud scenarios entire cloud provider outages!Columnar Store, Column Based, or Column Family? What? Ok, so you might have read a number of things about what Cassandra actually is. Let’s break this down. First off, a columnar or column store or column oriented database guarantees data location for a single column in a node on disk. The column may span a bunch of or all of the rows that depend on where or how you specify partitions. However, this isn’t what the Cassandra Database uses. Cassandra is a column-family database.A column-family storage architecture makes sure the data is stored based on locality of the data at the partition level, not the column level. Cassandra partitions group rows and columns split by a partition key, then clustered together by a specified clustering column or columns. To query Cassandra, because of this, you must know the partition key in order to avoid full data scans!Cassandra has these partitions that guarantee to be on the same node and sort strings table (referred to most commonly as an SSTable *) in the same location within that file. Even though, depending on the compaction strategy, this can change things and the partition can be split across multiple files on a disk. So really, data locality isn’t guaranteed.Column-family stores are great for high throughput writes and the ability to linearly scale horizontally (ya know, getting lots and lots of nodes in the cloud!). Reads using the partition key are extremely fast since this key points to exactly where the data resides. However, this often – at least last I know of – leads to a full scan of the data for any type of ad-hoc query.A sort of historically trivial but important point is the column-family term comes from the storage engine originally used based on a key value store. The value was a set of column value tuples, which where often referenced as family, and later this family was abstracted into partitions, and then the storage engine was matched to that abstraction. Whew, ok, so that’s a lot of knowledge being coagulated into a solid eh! [scuse’ my odd artful language use if you visualized that!]With all of this described, a that little history sprinkled in, when reading the description of Cassandra in the README.asc file of the actual Cassandra Github Repo things make just a little more sense. In the file it starts off with a description,Apache Cassandra is a highly-scalable partitioned row store. Rows are organized into tables with a required primary key.Partitioning means that Cassandra can distribute your data across multiple machines in an application-transparent matter. Cassandra will automatically repartition as machines are added and removed from the cluster.Row store means that like relational databases, Cassandra organizes data by rows and columns. The Cassandra Query Language (CQL) is a close relative of SQL.Now that I’ve covered the 101 level of what Cassandra is I’ll give a look at DataStax and their respective offering.DataStaxDataStax Enterprise at first glance might be a bit confusing since immediate questions pop up like, “Doesn’t DataStax make Cassandra?”, “Isn’t DataStax just selling support for Cassandra?”, or “Eh, wha, who is DataStax and what does this have to do with Cassandra?”. Well, I’m gonna tell ya all about where we are today regarding all of these things fit.PerformanceDataStax provides a whole selection of amenities around a database, which is derived from the Cassandra Distributed Database System. The core product and these amenities are built into what we refer to as the “DataStax Enterprise 6“. Some of specific differences are that the database engine itself has been modified out of band and now delivers 2x the performance of the standard Cassandra implemented database engine. I was somewhat dubious when I joined but after the third party benchmarks where completed that showed the difference I grew more confident. My confidence in this speed increase grew as I’ve gotten to work with the latest version I can tell in more than a few situations that it’s faster.Read Repair & NodeSyncIf you already use Cassandra, read repair works a certain way and that still works just fine in DataStax Enterprise 6. But one also has the option of using NodeSync which can help eliminate scripting, manual intervention, and other repair operations.Spark SQL ConnectivityThere’s also an always on SQL Engine for automated uptime for apps using DataStax Enterprise Analytics. This provides a better level of analytics requests and end -user analytics. Sort of on this related note, DataStax Studio also has notebook support for Spark SQL now. Writing one’s Spark SQL gets a little easier with this option.Multi-Cloud / Hybrid-CloudAnother huge advantage of DataStax Enterprise is going multi-cloud or hybrid-cloud with DataStax Enterprise Cassandra. Between the Lifecycle Manager (LCM), OpsCenter, and related tooling getting up and running with a cluster across a varying range of data-centers wherever they may be is quick and easy.SummaryI’ll be providing deeper dives into the particular technology, the specific differences, and more in the future. For now I’ll wrap up this post as I’ve got a few others coming distinctively related to distributed database systems themselves ranging from specific principles (like CAP Theorem) to operational (how to and best ways to manage) and development (patterns and practices of developing against) related topics.Overall the solutions that DataStax offers are solid advantages if you’re stepping into any large scale data (big data or whatever one would call their plethora of data) needs. Over the coming months I’ve got a lot of material – from architectural research and guidance to tactical coding implementation work – that I’ll be blogging about and providing. I’m really looking forward to exploring these capabilities, being the developer advocate to DataStax for the community of users, and learning a thing or three million. 47.671392 -122.376081
Let’s talk about the analogy of Apache Cassandra Datacenter & Racks to actual datacenter and racks. I kind of enjoy the use of the terms datacenter and racks to describe architectural elements of Cassandra. However, as time moves on the relationship between these terms and why they’re called datacenter and racks can be obfuscated.
Take for instance, a datacenter could just be a cloud provider, an actual physical datacenter location, a zone in Azure, or region in some other provider. What an actual Datacenter in Cassandra parlance actually is can vary, but the origins of why it’s called a Datacenter remains the same. The elements of racks also can vary, but also remain the same.
Origins: Racks & Datacenters?
Let’s cover the actual things in this industry we call datacenter and racks first, unrelated to Apache Cassandra terms.
Racks: The easiest way to describe a physical rack is to show pictures of datacenter racks via the ole’ Google images.
A rack is something that is located in a data-center, or even just someone’s garage in some odd scenarios. Ya know, if somebody wants serious hardware to work with. The rack then has a number of servers, often various kinds, within that rack itself. As you can see from the images above there’s a wide range of these racks.
Datacenter: Again the easiest way to describe a datacenter is to just look at a bunch of pictures of datacenter, albeit you see lots of racks again. But really, that’s what a datacenter is, is a building that has lots and lots of racks.
However in Apache Cassandra (and respectively DataStax Enterprise products) a datacenter and rack do not directly correlate to a physical rack or datacenter. The idea is more of an abstraction than hard mapping to the physical realm. In turn it is better to think of datacenter and racks as a way to structure and organize your DataStax Enterprise or Apache Cassandra architecture. From a tree perspective of organizing your cluster, think of things in this hierarchy.
Cluster
Datacenter(s)
Rack(s)
Server(s)
Node (vnode)
Apache Cassandra Datacenter
An Apache Cassandra Datacenter is a group of nodes, related and configured within a cluster for replication purposes. Setting up a specific set of related nodes into a datacenter helps to reduce latency, prevent transactions from impact by other workloads, and related effects. The replication factor can also be setup to write to multiple datacenter, providing additional flexibility in architectural design and organization. One specific element of datacenter to note is that they must contain only one node type:
Depending on the replication factor, data can be written to multiple datacenters. Datacenters must never span physical locations.Each datacenter usually contains only one node type. The node types are:
Transactional: Previously referred to as a Cassandra node.
DSE Graph: A graph database for managing, analyzing, and searching highly-connected data.
An Apache Cassandra Rack is a grouped set of servers. The architecture of Cassandra uses racks so that no replica is stored redundantly inside a singular rack, ensuring that replicas are spread around through different racks in case one rack goes down. Within a datacenter there could be multiple racks with multiple servers, as the hierarchy shown above would dictate.
To determine where data goes within a rack or sets of racks Apache Cassandra uses what is referred to as a snitch. A snitch determines which racks and datacenter a particular node belongs to, and by respect of that, determines where the replicas of data will end up. This replication strategy which is informed by the snitch can take the form of numerous kinds of snitches, some examples include;
SimpleSnitch – this snitch treats order as proximity. This is primarily only used when in a single-datacenter deployment.
Dynamic Snitching – the dynamic snitch monitors read latencies to avoid reading from hosts that have slowed down.
RackInferringSnitch – Proximity is determined by rack and datacenter, assumed corresponding to 3rd and 2nd octet of each node’s IP address. This particular snitch is often used as an example for writing a custom snitch class since it isn’t particularly useful unless it happens to match one’s deployment conventions.
In the future I’ll outline a few more snitches, how some of them work with more specific detail, and I’ll get into a whole selection of other topics. Be sure to subscribe to the blog, the ole’ RSS feed works great too, and follow @CompositeCode for blog updates. For discourse and hot takes follow me @Adron.
First steps. Let’s get .NET installed and setup. I’m running Ubuntu 18.04 for this setup and start of project. To install .NET on Ubuntu one needs to go through a multi-command process of keys and some other stuff, fortunately Microsoft’s teams have made this almost easy by providing the commands for the various Linux distributions here. The commands I ran are as follows to get all this initial setup done.
After all this I could then install the .NET SDK. It’s been so long since I actually installed .NET on anything that I wasn’t sure if I just needed the runtime, the SDK, or what I’d actually need. I just assumed it would be safe to install the SDK and then install the runtime too.
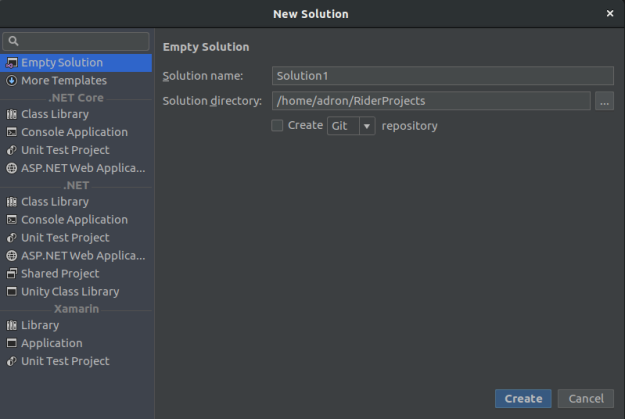
Alright. Now with this installed, I wanted to also see if Jetbrains Rider would detect – or at least what would I have to do – to have the IDE detect that .NET is now installed. So I opened up the IDE to see what the results would be. Over the left hand side of the new solution dialog, if anything isn’t installed Rider usually will display a message that X whatever needs installed. But it looked like everything is showing up as installed, “yay for things working (at this point)!”
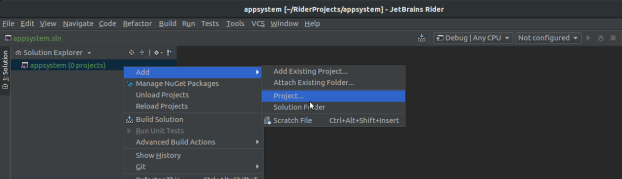
Next up is to get a solution started with the pertinent projects for what I want to build.
For the next stage I created three projects.
InteroperationalBlackBox – A basic class library that will be used by a console application or whatever other application or service that may need access to the specific business logic or what not.
InteroperationalBlackBox.Tests – An xunit testing project for testing anything that might need some good ole’ testing.
InteroperationalBlackBox.Cli – A console application (CLI) that I’ll use to interact with the class library and add capabilities going forward.
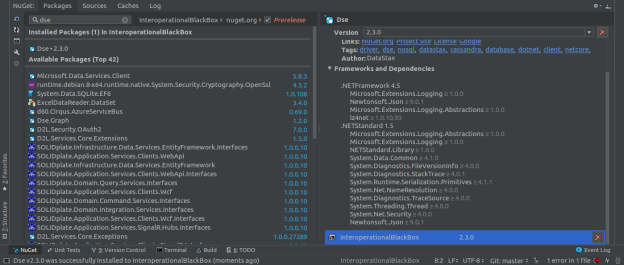
Alright, now that all the basic projects are setup in the solution, I’ll go out and see about the .NET DataStax Enterprise driver. Inside Jetbrains Rider I can right click on a particular project that I want to add or manage dependencies for. I did that and then put “dse” in the search box. The dialog pops up from the bottom of the IDE and you can add it by clicking on the bottom right plus sign in the description box to the right. Once you click the plus sign, once installed, it becomes a little red x.
Alright. Now it’s almost time to get some code working. We need ourselves a database first however. I’m going to setup a cluster in Google Cloud Platform (GCP), but feel free to use whatever cluster you’ve got. These instructions will basically be reusable across wherever you’ve got your cluster setup. I wrote up a walk through and instructions for the GCP Marketplace a few weeks ago. I used the same offering to get this example cluster up and running to use. So, now back to getting the first snippets of code working.
Let’s write a test first.
[Fact]
public void ConfirmDatabase_Connects_False()
{
var box = new BlackBox();
Assert.Equal(false, box.ConfirmConnection());
}
In this test, I named the class called BlackBox and am planning to have a parameterless constructor. But as things go tests are very fluid, or ought to be, and I may change it in the next iteration. I’m thinking, at least to get started, that I’ll have a method to test and confirm a connection for the CLI. I’ve named it ConfirmConnection for that purpose. Initially I’m going to test for false, but that’s primarily just to get started. Now, time to implement.
namespace InteroperabilityBlackBox
using System;
using Dse;
using Dse.Auth;
namespace InteroperabilityBlackBox
{
public class BlackBox
{
public BlackBox()
{}
public bool ConfirmConnection()
{
return false;
}
}
}
That gives a passing test and I move forward. For more of the run through of moving from this first step to the finished code session check out this
By the end of the coding session I had a few tests.
using Xunit;
namespace InteroperabilityBlackBox.Tests
{
public class MakingSureItWorksIntegrationTests
{
[Fact]
public void ConfirmDatabase_Connects_False()
{
var box = new BlackBox();
Assert.Equal(false, box.ConfirmConnection());
}
[Fact]
public void ConfirmDatabase_PassedValuesConnects_True()
{
var box = new BlackBox("cassandra", "", "");
Assert.Equal(false, box.ConfirmConnection());
}
[Fact]
public void ConfirmDatabase_PassedValuesConnects_False()
{
var box = new BlackBox("cassandra", "notThePassword", "");
Assert.Equal(false, box.ConfirmConnection());
}
}
}
The respective code for connecting to the database cluster, per the walk through I wrote about here, at session end looked like this.
using System;
using Dse;
using Dse.Auth;
namespace InteroperabilityBlackBox
{
public class BlackBox : IBoxConnection
{
public BlackBox(string username, string password, string contactPoint)
{
UserName = username;
Password = password;
ContactPoint = contactPoint;
}
public BlackBox()
{
UserName = "ConfigValueFromSecretsVault";
Password = "ConfigValueFromSecretsVault";
ContactPoint = "ConfigValue";
}
public string ContactPoint { get; set; }
public string UserName { get; set; }
public string Password { get; set; }
public bool ConfirmConnection()
{
IDseCluster cluster = DseCluster.Builder()
.AddContactPoint(ContactPoint)
.WithAuthProvider(new DsePlainTextAuthProvider(UserName, Password))
.Build();
try
{
cluster.Connect();
return true;
}
catch (Exception e)
{
Console.WriteLine(e);
return false;
}
}
}
}
After I wrapped up the session two things stood out that needed fixed for the next session. I’ll be sure to add these as objectives for the next coding session at 3pm PST on Thursday.
The tests really needed to more resiliently confirm the integrations that I was working to prove out. My plan at this point is to add some Docker images that would provide the development integration tests a point to work against. This would alleviate the need for something outside of the actual project in the repository to exist. Removing that fragility.
The application, in its “Black Box”, should do something. For the next session we’ll write up some feature requests we’d want, or maybe someone has some suggestions of functionality they’d like to see implemented in a CLI using .NET Core working against a DataStax Enterprise Cassandra Database Cluster? Feel free to leave a comment or three about a feature, I’ll work on adding it during the next session.
SITREP = Situation Report. It’s military speak. ??♂️
Apache Cassandra is one of the most popular databases in use today. It has many characteristics and distinctive architectural details. In this post I’ll provide a description and some details for a number of these features and characteristics, divided as such. Then, after that (i.e. toward the end, so skip there if you just want to the differences) I’m doing to summarize key differences with the latest release of the DataStax Enterprise 6 version of the database.
Cassandra Characteristics
Cassandra is a linearly scalable, highly available, fault tolerant, distributed database. That is, just to name a few of the most important characteristics. The Cassandra database is also cross-platform (runs on any operating systems), multi-cloud (runs on and across multiple clouds), and can survive regional data center outages or even in multi-cloud scenarios entire cloud provider outages!
Columnar Store, Column Based, or Column Family? What? Ok, so you might have read a number of things about what Cassandra actually is. Let’s break this down. First off, a columnar or column store or column oriented database guarantees data location for a single column in a node on disk. The column may span a bunch of or all of the rows that depend on where or how you specify partitions. However, this isn’t what the Cassandra Database uses. Cassandra is a column-family database.
A column-family storage architecture makes sure the data is stored based on locality of the data at the partition level, not the column level. Cassandra partitions group rows and columns split by a partition key, then clustered together by a specified clustering column or columns. To query Cassandra, because of this, you must know the partition key in order to avoid full data scans!
Cassandra has these partitions that guarantee to be on the same node and sort strings table (referred to most commonly as an SSTable *) in the same location within that file. Even though, depending on the compaction strategy, this can change things and the partition can be split across multiple files on a disk. So really, data locality isn’t guaranteed.
Column-family stores are great for high throughput writes and the ability to linearly scale horizontally (ya know, getting lots and lots of nodes in the cloud!). Reads using the partition key are extremely fast since this key points to exactly where the data resides. However, this often – at least last I know of – leads to a full scan of the data for any type of ad-hoc query.
A sort of historically trivial but important point is the column-family term comes from the storage engine originally used based on a key value store. The value was a set of column value tuples, which where often referenced as family, and later this family was abstracted into partitions, and then the storage engine was matched to that abstraction. Whew, ok, so that’s a lot of knowledge being coagulated into a solid eh! [scuse’ my odd artful language use if you visualized that!]
With all of this described, a that little history sprinkled in, when reading the description of Cassandra in the README.asc file of the actual Cassandra Github Repo things make just a little more sense. In the file it starts off with a description,
Apache Cassandra is a highly-scalable partitioned row store. Rows are organized into tables with a required primary key.
Partitioning means that Cassandra can distribute your data across multiple machines in an application-transparent matter. Cassandra will automatically repartition as machines are added and removed from the cluster.
Row store means that like relational databases, Cassandra organizes data by rows and columns. The Cassandra Query Language (CQL) is a close relative of SQL.
Now that I’ve covered the 101 level of what Cassandra is I’ll give a look at DataStax and their respective offering.
DataStax
DataStax Enterprise at first glance might be a bit confusing since immediate questions pop up like, “Doesn’t DataStax make Cassandra?”, “Isn’t DataStax just selling support for Cassandra?”, or “Eh, wha, who is DataStax and what does this have to do with Cassandra?”. Well, I’m gonna tell ya all about where we are today regarding all of these things fit.
Performance
DataStax provides a whole selection of amenities around a database, which is derived from the Cassandra Distributed Database System. The core product and these amenities are built into what we refer to as the “DataStax Enterprise 6“. Some of specific differences are that the database engine itself has been modified out of band and now delivers 2x the performance of the standard Cassandra implemented database engine. I was somewhat dubious when I joined but after the third party benchmarks where completed that showed the difference I grew more confident. My confidence in this speed increase grew as I’ve gotten to work with the latest version I can tell in more than a few situations that it’s faster.
Read Repair & NodeSync
If you already use Cassandra, read repair works a certain way and that still works just fine in DataStax Enterprise 6. But one also has the option of using NodeSync which can help eliminate scripting, manual intervention, and other repair operations.
Spark SQL Connectivity
There’s also an always on SQL Engine for automated uptime for apps using DataStax Enterprise Analytics. This provides a better level of analytics requests and end -user analytics. Sort of on this related note, DataStax Studio also has notebook support for Spark SQL now. Writing one’s Spark SQL gets a little easier with this option.
Multi-Cloud / Hybrid-Cloud
Another huge advantage of DataStax Enterprise is going multi-cloud or hybrid-cloud with DataStax Enterprise Cassandra. Between the Lifecycle Manager (LCM), OpsCenter, and related tooling getting up and running with a cluster across a varying range of data-centers wherever they may be is quick and easy.
Summary
I’ll be providing deeper dives into the particular technology, the specific differences, and more in the future. For now I’ll wrap up this post as I’ve got a few others coming distinctively related to distributed database systems themselves ranging from specific principles (like CAP Theorem) to operational (how to and best ways to manage) and development (patterns and practices of developing against) related topics.
Overall the solutions that DataStax offers are solid advantages if you’re stepping into any large scale data (big data or whatever one would call their plethora of data) needs. Over the coming months I’ve got a lot of material – from architectural research and guidance to tactical coding implementation work – that I’ll be blogging about and providing. I’m really looking forward to exploring these capabilities, being the developer advocate to DataStax for the community of users, and learning a thing or three million.
Claim Your Free Planet Cassandra Contributor T-shirt!
Make your contribution and score a FREE Planet Cassandra Contributor T-Shirt! We value our incredible Cassandra community, and we want to express our gratitude by sending an exclusive Planet Cassandra Contributor T-Shirt you can wear with pride.
Join Our Newsletter!
Sign up below to receive email updates and see what's going on with our company